
MaMuJoCo (Multi-Agent MuJoCo)¶
MaMuJoCo was introduced in “FACMAC: Factored Multi-Agent Centralised Policy Gradients”.
There are 2 types of Environments, included (1) multi-agent factorizations of Gymnasium/MuJoCo tasks and (2) new complex MuJoCo tasks meant to me solved with multi-agent Algorithms.
Gymnasium-Robotics/MaMuJoCo Represents the first, easy to use Framework for research of agent factorization.
API¶
MaMuJoCo mainly uses the PettingZoo.ParallelAPI, but also supports a few extra functions:
- gymnasium_robotics.mamujoco_v1.parallel_env.map_local_actions_to_global_action(self, actions: dict[str, ndarray]) ndarray¶
Maps multi agent actions into single agent action space.
- Parameters:
action – An dict representing the action of each agent
- Returns:
The action of the whole domain (is what eqivilent single agent action would be)
- Raises:
AssertionError – If the Agent action factorization is badly defined (if an action is double defined or not defined at all)
- gymnasium_robotics.mamujoco_v1.parallel_env.map_global_action_to_local_actions(self, action: ndarray) dict[str, ndarray]¶
Maps single agent action into multi agent action spaces.
- Parameters:
action – An array representing the actions of the single agent for this domain
- Returns:
A dictionary of actions to be performed by each agent
- Raises:
AssertionError – If the Agent action factorization sizes are badly defined
- gymnasium_robotics.mamujoco_v1.parallel_env.map_global_state_to_local_observations(self, global_state: ndarray[float64]) dict[str, ndarray[float64]]¶
Maps single agent observation into multi agent observation spaces.
- Parameters:
global_state – the global_state (generated from MaMuJoCo.state())
- Returns:
A dictionary of states that would be observed by each agent given the ‘global_state’
- gymnasium_robotics.mamujoco_v1.parallel_env.map_local_observations_to_global_state(self, local_observation: ndarray[float64]) ndarray[float64]¶
Maps multi agent observations into single agent observation space.
- Parameters:
local_obserations – the local observation of each agents (generated from MaMuJoCo.step())
- Returns:
the global observations that correspond to a single agent (what you would get with MaMuJoCo.state())
- gymnasium_robotics.mamujoco_v1.get_parts_and_edges(label: str, partitioning: str | None) tuple[list[tuple[Node, ...]], list[HyperEdge], list[Node]]¶
Gets the mujoco Graph (nodes & edges) given an optional partitioning,.
- Parameters:
label – the mujoco task to partition
partitioning – the partioneing scheme
- Returns:
the partition of the mujoco graph nodes, the graph edges, and global nodes
MaMuJoCo also supports the PettingZoo.AECAPI but does not expose extra functions.
Arguments¶
- gymnasium_robotics.mamujoco_v1.parallel_env.__init__(self, scenario: str, agent_conf: str | None, agent_obsk: int | None = 1, agent_factorization: dict[str, any] | None = None, local_categories: list[list[str]] | None = None, global_categories: tuple[str, ...] | None = None, render_mode: str | None = None, gym_env: MujocoEnv | None = None, **kwargs)¶
Init.
- Parameters:
scenario – The Task/Environment, valid values: “Ant”, “HalfCheetah”, “Hopper”, “HumanoidStandup”, “Humanoid”, “Reacher”, “Swimmer”, “Pusher”, “Walker2d”, “InvertedPendulum”, “InvertedDoublePendulum”, “ManySegmentSwimmer”, “ManySegmentAnt”, “CoupledHalfCheetah”
agent_conf – Typical values: ‘${Number Of Agents}x${Number Of Segments per Agent}${Optionally Additional options}’, eg ‘1x6’, ‘2x4’, ‘2x4d’, If it set to None the task becomes single agent (the agent observes the entire environment, and performs all the actions)
agent_obsk – Number of nearest joints to observe, If set to 0 it only observes local state, If set to 1 it observes local state + 1 joint over, If set to 2 it observes local state + 2 joints over, If it set to None the task becomes single agent (the agent observes the entire environment, and performs all the actions) The Default value is: 1
agent_factorization – A custom factorization of the MuJoCo environment (overwrites agent_conf), see DOC [how to create new agent factorizations](https://robotics.farama.org/envs/MaMuJoCo/index.html#how-to-create-new-agent-factorizations).
local_categories – The categories of local observations for each observation depth, It takes the form of a list where the k-th element is the list of observable items observable at the k-th depth For example: if it is set to [[“qpos, qvel”], [“qvel”]] then means each agent observes its own position and velocity elements, and it’s neighbors velocity elements. The default is: Check each environment’s page on the “observation space” section.
global_categories – The categories of observations extracted from the global observable space, For example: if it is set to (“qpos”) out of the globally observable items of the environment, only the position items will be observed. The default is: (“qpos”, “qvel”)
render_mode – See [Gymnasium/MuJoCo](https://gymnasium.farama.org/environments/mujoco/), valid values: ‘human’, ‘rgb_array’, ‘depth_array’
gym_env – A custom MujocoEnv environment, overrides generation of environment by MaMuJoCo.
kwargs – Additional arguments passed to the [Gymnasium/MuJoCo](https://gymnasium.farama.org/environments/mujoco/) environment, Note: arguments that change the observation space will not work.
Raises – NotImplementedError: When the scenario is not supported (not part of of the valid values).
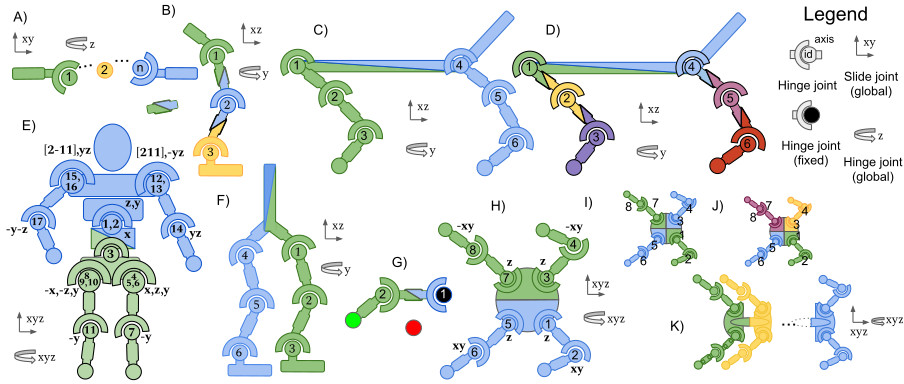
How to create new agent factorizations¶
MaMuJoCo-v1 not only supports the existing factorization, but also supports creating new factorizations.
example ‘Ant-v5’, ‘8x1’¶
In this example, we will create an agent factorization not present in Gymnasium-Robotics/MaMuJoCo the “Ant”/’8x1’, where each agent controls a single joint/action (first implemented by safe-MaMuJoCo).
first we will load the graph of MaMuJoCo:
>>> from gymnasium_robotics.mamujoco_v1 import get_parts_and_edges
>>> unpartioned_nodes, edges, global_nodes = get_parts_and_edges('Ant-v5', None)
The unpartioned_nodes contain the nodes of the MaMuJoCo graph.
The edges well, contain the edges of the graph.
And the global_nodes a set of observations for all agents.
To create our ‘8x1’ partition we will need to partition the unpartioned_nodes:
>>> unpartioned_nodes
[(hip1, ankle1, hip2, ankle2, hip3, ankle3, hip4, ankle4)]
>>> partioned_nodes = [(unpartioned_nodes[0][0],), (unpartioned_nodes[0][1],), (unpartioned_nodes[0][2],), (unpartioned_nodes[0][3],), (unpartioned_nodes[0][4],), (unpartioned_nodes[0][5],), (unpartioned_nodes[0][6],), (unpartioned_nodes[0][7],)]
>>> partioned_nodes
[(hip1,), (ankle1,), (hip2,), (ankle2,), (hip3,), (ankle3,), (hip4,), (ankle4,)]
Finally package the partitions and create our environment:
>>> my_agent_factorization = {"partition": partioned_nodes, "edges": edges, "globals": global_nodes}
>>> gym_env = mamujoco_v1('Ant', '8x1', agent_factorization=my_agent_factorization)
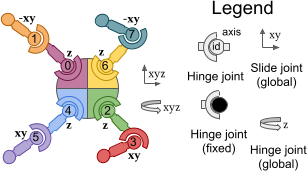
example ‘boston dynamics spot arm’ with custom ‘quadruped|arm’ factorization¶
Here we are Factorizing the “Boston Dynamics Spot with arm” robot with the robot model from Menagarie, into 1 agent for the locomoting quadruped component and 1 agent for the manipulator arm component. We are using the robot model from MuJoCo Menagerie.
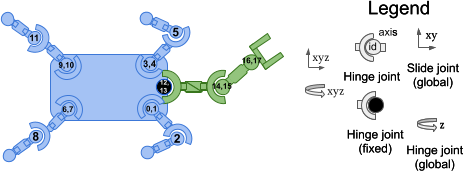
from gymnasium_robotics import mamujoco_v1
from gymnasium_robotics.envs.multiagent_mujoco.obsk import Node, HyperEdge
# Define the factorization graph
freejoint = Node(
"freejoint",
None,
None,
None,
extra_obs={
"qpos": lambda data: data.qpos[2:7],
"qvel": lambda data: data.qvel[:6],
},
)
fl_hx = Node("fl_hx", -19, -19, 0)
fl_hy = Node("fl_hy", -18, -18, 1)
fl_kn = Node("fl_kn", -17, -17, 2)
fr_hx = Node("fr_hx", -16, -16, 3)
fr_hy = Node("fr_hy", -15, -15, 4)
fr_kn = Node("fr_kn", -14, -14, 5)
hl_hx = Node("hl_hx", -13, -13, 6)
hl_hy = Node("hl_hy", -12, -12, 7)
hl_kn = Node("hl_kn", -11, -11, 8)
hr_hx = Node("hr_hx", -10, -10, 9)
hr_hy = Node("hr_hy", -9, -9, 10)
hr_kn = Node("hr_kn", -8, -8, 11)
arm_sh0 = Node("arm_sh0", -7, -7, 12)
arm_sh1 = Node("arm_sh1", -6, -6, 13)
arm_el0 = Node("arm_el0", -5, -5, 14)
arm_el1 = Node("arm_el1", -4, -4, 15)
arm_wr0 = Node("arm_wr0", -3, -3, 16)
arm_wr1 = Node("arm_wr1", -2, -2, 17)
arm_f1x = Node("arm_f1x", -1, -1, 18)
parts = [
( # Locomoting Quadruped Component
fl_hx,
fl_hy,
fl_kn,
fr_hx,
fr_hy,
fr_kn,
hl_hx,
hl_hy,
hl_kn,
hr_hx,
hr_hy,
hr_kn,
),
( # Arm Manipulator Component
arm_sh0,
arm_sh1,
arm_el0,
arm_el1,
arm_wr0,
arm_wr1,
arm_f1x,
),
]
edges = [
HyperEdge(fl_hx, fl_hy, fl_kn),
HyperEdge(fr_hx, fr_hy, fr_kn),
HyperEdge(hl_hx, hl_hy, hl_kn),
HyperEdge(hr_hx, hr_hy, hr_kn),
HyperEdge( # Main "body" connections
fl_hx,
fl_hy,
fr_hx,
fr_hy,
hl_hx,
hl_hy,
hr_hx,
hr_hy,
arm_sh0,
arm_sh1,
),
HyperEdge(arm_sh0, arm_sh1, arm_el0, arm_el1),
HyperEdge(arm_el0, arm_el1, arm_wr0, arm_wr1),
HyperEdge(arm_wr0, arm_wr1, arm_f1x),
]
global_nodes = [freejoint]
my_agent_factorization = {"partition": parts, "edges": edges, "globals": global_nodes}
env = mamujoco_v1.parallel_env(
"Ant",
"quadruped|arm",
agent_factorization=my_agent_factorization,
xml_file="./mujoco_menagerie/boston_dynamics_spot/scene_arm.xml",
)
Of course, you also need to add new elements to the environment and define your task, to do something useful.
Version History¶
v1:
Based on
Gymnasium/MuJoCo-v5instead ofGymnasium/MuJoCo-v4(https://github.com/Farama-Foundation/Gymnasium/pull/572).When
factorizatoion=None, theenv.gent_action_partitions.dummy_nodenow containsaction_id(it used to beNone).Added
map_local_observations_to_global_state& optimized runtime performance ofmap_global_state_to_local_observations.Added
gym_envargument for using environment wrappers, also can be used to load third-partyGymnasium.MujocoEnvenvironments.
v0: Initial version release on gymnasium, and is a fork of the original multiagent_mujuco,
Based on
Gymnasium/MuJoCo-v4instead ofGym/MuJoCo-v2.Uses PettingZoo APIs instead of an original API.
Added support for custom agent factorizations.
Added new functions
MultiAgentMujocoEnv.map_global_action_to_local_actions,MultiAgentMujocoEnv.map_local_actions_to_global_action,MultiAgentMujocoEnv.map_global_state_to_local_observations.